HuggingFace, Transformers, and Conformal Prediction - Part 1
conformal prediction
transformers
llm
Julia
For this year’s edition of the ING Analytics Experiment Week, we put ConformalPrediction.jl to work and built a chatbot that can be used for Conformal Intent Recognition.
Large Language Models are all the buzz right now. They are used for a variety of tasks, including text classification, question answering, and text generation. In this tutorial, we will show how to conformalize a transformer language model for text classification. We will use the Banking77 dataset (Casanueva et al. 2020), which consists of 13,083 queries from 77 intents. On the model side, we will use the DistilRoBERTa model, which is a distilled version of RoBERTa(Liu et al. 2019) finetuned on the Banking77 dataset.
🤗 HuggingFace Model
The model can be loaded from HF straight into our running Julia session using the Transformers.jl package. Below we load the tokenizer tkr and the model mod. The tokenizer is used to convert the text into a sequence of integers, which is then fed into the model. The model outputs a hidden state, which is then fed into a classifier to get the logits for each class. Finally, the logits are then passed through a softmax function to get the corresponding predicted probabilities. Below we run a few queries through the model to see how it performs.
Code
# Load model from HF 🤗:tkr = hgf"mrm8488/distilroberta-finetuned-banking77:tokenizer"mod = hgf"mrm8488/distilroberta-finetuned-banking77:ForSequenceClassification"# Test model:query = ["What is the base of the exchange rates?","Why is my card not working?","My Apple Pay is not working, what should I do?",]a =encode(tkr, query)b = mod.model(a)c = mod.cls(b.hidden_state)d =softmax(c.logit)[labels[i] for i in Flux.onecold(d)]
Since our package is interfaced to MLJ.jl, we need to define a wrapper model that conforms to the MLJ interface. In order to add the model for general use, we would probably go through MLJFlux.jl, but for this tutorial, we will make our life easy and simply overload the MLJBase.fit and MLJBase.predict methods. Since the model from HF is already pre-trained and we are not interested in further fine-tuning, we will simply return the model object in the MLJBase.fit method. The MLJBase.predict method will then take the model object and the query and return the predicted probabilities. We also need to define the MLJBase.target_scitype and MLJBase.predict_mode methods. The former tells MLJ what the output type of the model is, and the latter can be used to retrieve the label with the highest predicted probability.
1.875274 seconds (8.61 M allocations: 631.254 MiB, 3.20% gc time, 87.70% compilation time)
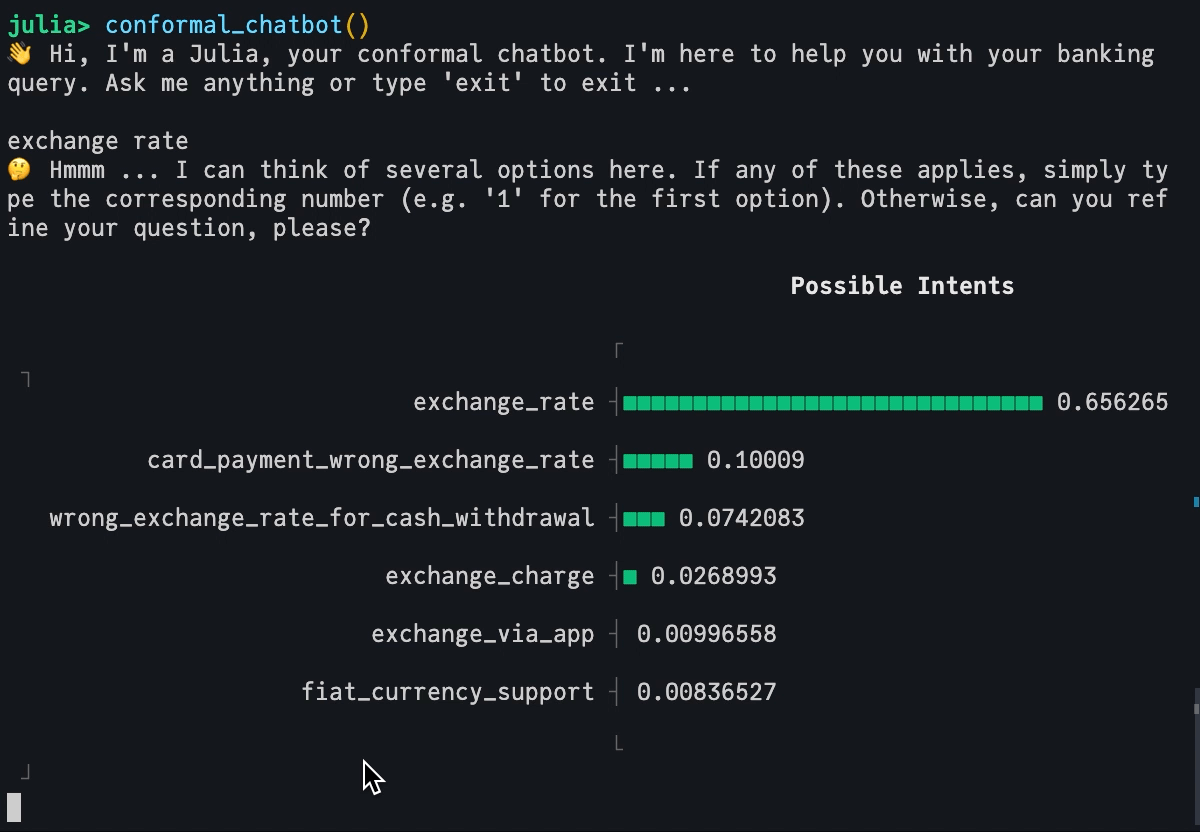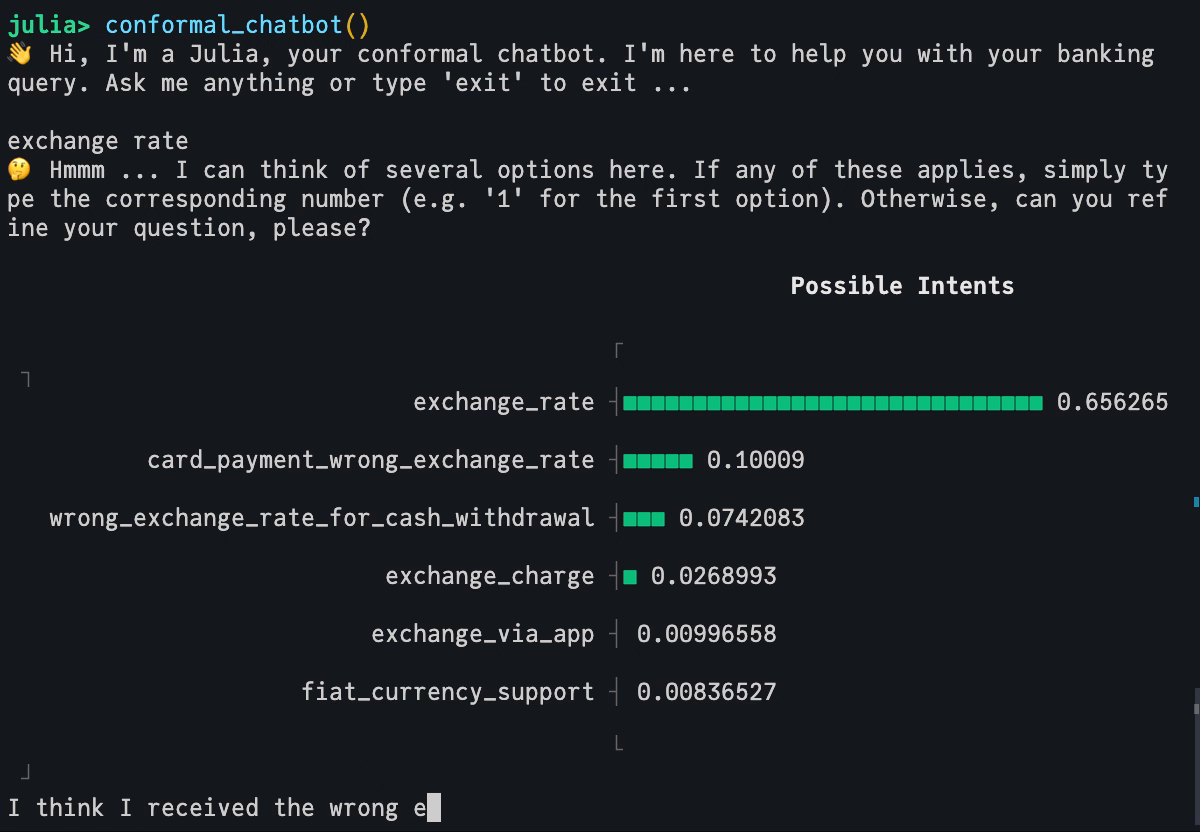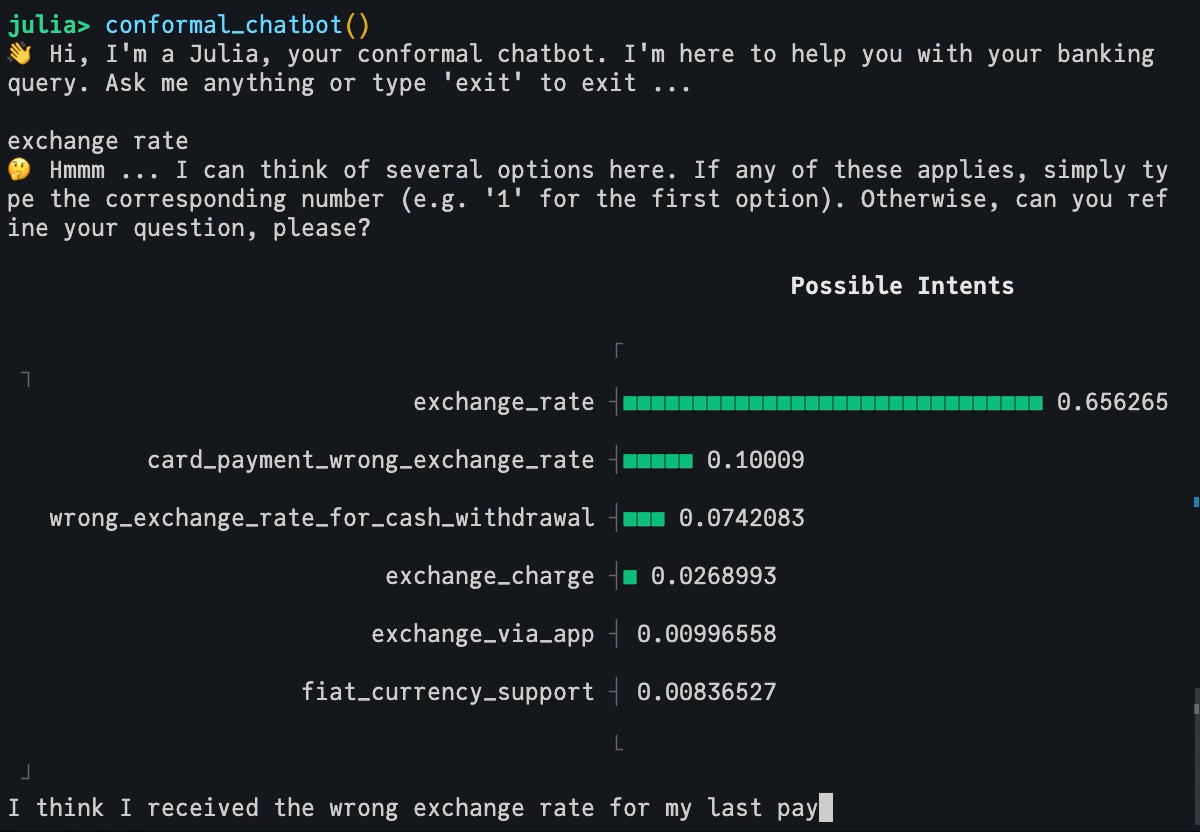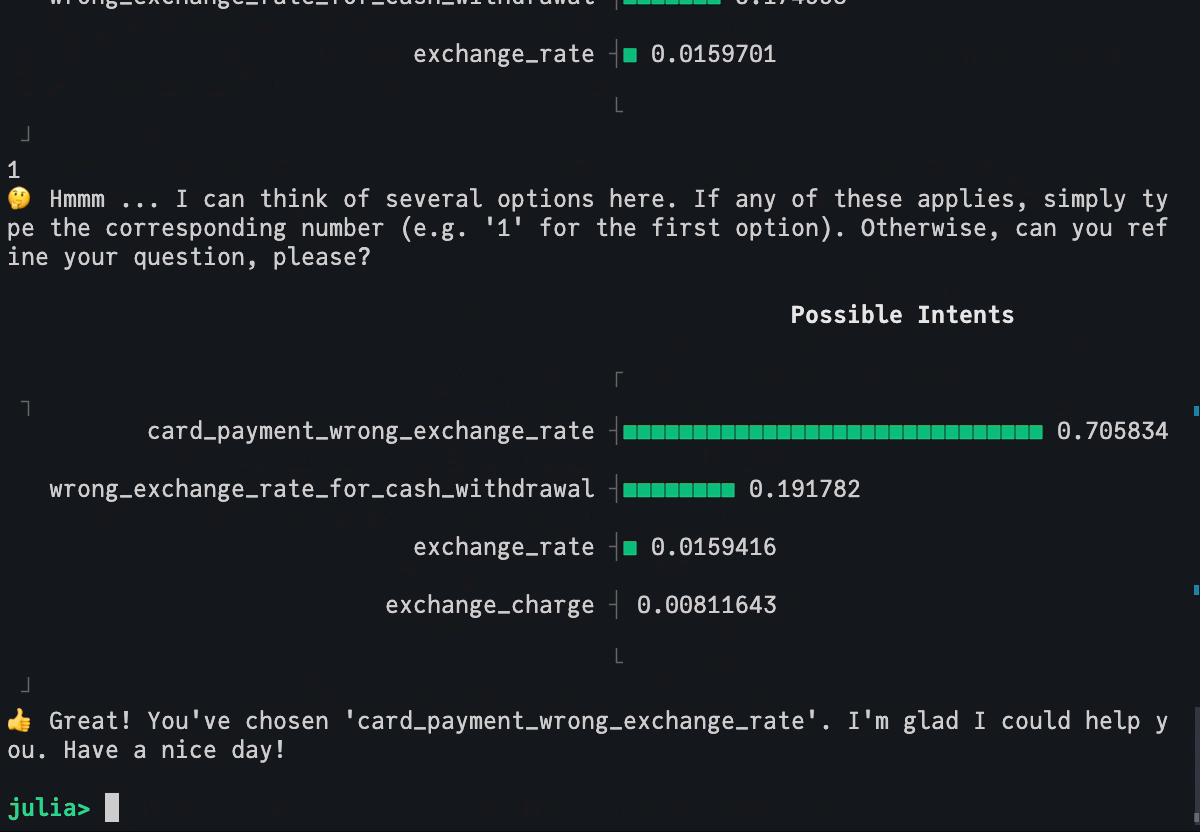
🤖 Conformal Chatbot
To turn the wrapped, pre-trained model into a conformal intent classifier, we can now rely on standard API calls. We first wrap our atomic model where we also specify the desired coverage rate and method. Since even simple forward passes are computationally expensive for our (small) LLM, we rely on Simple Inductive Conformal Classification.
Finally, we use our conformal LLM to build a simple yet powerful chatbot that runs directly in the Julia REPL. Without dwelling on the details too much, the conformal_chatbot works as follows:
Prompt user to explain their intent.
Feed user input through conformal LLM and present the output to the user.
If the conformal prediction set includes more than one label, prompt the user to either refine their input or choose one of the options included in the set.
Code
mach =Serialization.deserialize("../dev/private/simple_inductive.jls")functionprediction_set(mach, query::String) p̂ = MLJBase.predict(mach, query)[1] probs =pdf.(p̂, collect(1:77)) in_set =findall(probs .!=0) labels_in_set = labels[in_set] probs_in_set = probs[in_set] _order =sortperm(-probs_in_set) plt = UnicodePlots.barplot(labels_in_set[_order], probs_in_set[_order], title="Possible Intents")return labels_in_set, pltendfunctionconformal_chatbot()println("👋 Hi, I'm a Julia, your conformal chatbot. I'm here to help you with your banking query. Ask me anything or type 'exit' to exit ...\n") completed =false queries =""while !completed query =readline() queries = queries *","* query labels, plt =prediction_set(mach, queries)iflength(labels) >1println("🤔 Hmmm ... I can think of several options here. If any of these applies, simply type the corresponding number (e.g. '1' for the first option). Otherwise, can you refine your question, please?\n")println(plt)elseprintln("🥳 I think you mean $(labels[1]). Correct?")end# Exit:if query =="exit"println("👋 Bye!")breakendif query ∈string.(collect(1:77))println("👍 Great! You've chosen '$(labels[parse(Int64, query)])'. I'm glad I could help you. Have a nice day!") completed =trueendendend
Below we show the output for two example queries. The first one is very ambiguous. As expected, the size of the prediction set is therefore large.
Below we include a short demo video that shows the REPL-based chatbot in action.
🌯 Wrapping Up
This work was done in collaboration with colleagues at ING as part of the ING Analytics 2023 Experiment Week. Our team demonstrated that Conformal Prediction provides a powerful and principled alternative to top-K intent classification. We won the first prize by popular vote.
There are a lot of things that can be improved. As far as LLMs are concerned, we have of course used a fairly small model here. In terms of Conformal Prediction, we have relied on simple inductive conformal classification. This is a good starting point, but there are more advanced methods available (and implemented in the package). Another thing we did not take into consideration here is that we have many outcome classes and may in practice be interested in achieving class-conditional coverage. Stay tuned for more!
🎓 References
Casanueva, Iñigo, Tadas Temčinas, Daniela Gerz, Matthew Henderson, and Ivan Vulić. 2020. “Efficient IntentDetection with DualSentenceEncoders.” In Proceedings of the 2nd Workshop on NaturalLanguageProcessing for ConversationalAI, 38–45. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.nlp4convai-1.5.
Liu, Yinhan, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. “RoBERTa: A Robustly Optimized BERT Pretraining Approach.”https://arxiv.org/abs/1907.11692.
Citation
BibTeX citation:
@online{altmeyer2023,
author = {Altmeyer, Patrick},
title = {Building a {Conformal} {Chatbot} in {Julia}},
date = {2023-07-05},
url = {https://www.taija.org/blog/posts/conformal-llm/},
langid = {en}
}
---title: Building a Conformal Chatbot in Juliasubtitle: HuggingFace, Transformers, and Conformal Prediction - Part 1date: '2023-07-05'categories: - conformal prediction - transformers - llm - Juliadescription: >- For this year's edition of the ING Analytics Experiment Week, we put `ConformalPrediction.jl` to work and built a chatbot that can be used for Conformal Intent Recognition.author: - name: Patrick Altmeyer url: www.patalt.org orcid: 0000-0003-4726-8613 affiliation: - name: Delft University of Technology url: https://www.tudelft.nl/en/image: www/intro.gifjupyter: julia-1.10draft: false---```{julia}#| echo: falseBLOG_DIR = "blog/posts/conformal-llm"using Pkg; Pkg.activate(BLOG_DIR)using ConformalPredictionusing CSVusing DataFramesusing Fluxusing MLJBaseusing Serializationusing Transformersusing Transformers.TextEncodersusing Transformers.HuggingFaceusing UnicodePlots```<div class="intro-gif"> <figure> <img src="www/intro.gif" style="width: 400px; height: 300px;"> <figcaption>Short demo of our conformal chatbot.</figcaption> </figure></div>Large Language Models are all the buzz right now. They are used for a variety of tasks, including text classification, question answering, and text generation. In this tutorial, we will show how to conformalize a transformer language model for text classification. We will use the [Banking77](https://arxiv.org/abs/2003.04807) dataset [@casanueva2020efficient], which consists of 13,083 queries from 77 intents. On the model side, we will use the [DistilRoBERTa](https://huggingface.co/mrm8488/distilroberta-finetuned-banking77) model, which is a distilled version of [RoBERTa](https://arxiv.org/abs/1907.11692)[@liu2019roberta] finetuned on the Banking77 dataset.```{julia}#| echo: false# Get labels:df_labels = CSV.read(joinpath(BLOG_DIR,"data/labels.csv"), DataFrame, drop=[1])labels = df_labels[:,1]# Get data:df_train = CSV.read(joinpath(BLOG_DIR,"data/train.csv"), DataFrame, drop=[1])df_cal = CSV.read(joinpath(BLOG_DIR,"data/calibration.csv"), DataFrame, drop=[1])df_full_train = vcat(df_train, df_cal)train_ratio = round(nrow(df_train)/nrow(df_full_train), digits=2)df_test = CSV.read(joinpath(BLOG_DIR,"data/test.csv"), DataFrame, drop=[1])# Preprocess data:queries_train, y_train = collect(df_train.text), categorical(df_train.labels .+ 1)queries_cal, y_cal = collect(df_cal.text), categorical(df_cal.labels .+ 1)queries, y = collect(df_full_train.text), categorical(df_full_train.labels .+ 1)queries_test, y_test = collect(df_test.text), categorical(df_test.labels .+ 1)```## 🤗 HuggingFace ModelThe model can be loaded from HF straight into our running Julia session using the [`Transformers.jl`](https://github.com/chengchingwen/Transformers.jl/tree/master) package. Below we load the tokenizer `tkr` and the model `mod`. The tokenizer is used to convert the text into a sequence of integers, which is then fed into the model. The model outputs a hidden state, which is then fed into a classifier to get the logits for each class. Finally, the logits are then passed through a softmax function to get the corresponding predicted probabilities. Below we run a few queries through the model to see how it performs.```{julia}#| output: true# Load model from HF 🤗:tkr = hgf"mrm8488/distilroberta-finetuned-banking77:tokenizer"mod = hgf"mrm8488/distilroberta-finetuned-banking77:ForSequenceClassification"# Test model:query = [ "What is the base of the exchange rates?", "Why is my card not working?", "My Apple Pay is not working, what should I do?",]a = encode(tkr, query)b = mod.model(a)c = mod.cls(b.hidden_state)d = softmax(c.logit)[labels[i] for i in Flux.onecold(d)]```## 🔁 `MLJ` InterfaceSince our package is interfaced to [`MLJ.jl`](https://alan-turing-institute.github.io/MLJ.jl/dev/), we need to define a wrapper model that conforms to the `MLJ` interface. In order to add the model for general use, we would probably go through [`MLJFlux.jl`](https://github.com/FluxML/MLJFlux.jl), but for this tutorial, we will make our life easy and simply overload the `MLJBase.fit` and `MLJBase.predict` methods. Since the model from HF is already pre-trained and we are not interested in further fine-tuning, we will simply return the model object in the `MLJBase.fit` method. The `MLJBase.predict` method will then take the model object and the query and return the predicted probabilities. We also need to define the `MLJBase.target_scitype` and `MLJBase.predict_mode` methods. The former tells `MLJ` what the output type of the model is, and the latter can be used to retrieve the label with the highest predicted probability.```{julia}struct IntentClassifier <: MLJBase.Probabilistic tkr::TextEncoders.AbstractTransformerTextEncoder mod::HuggingFace.HGFRobertaForSequenceClassificationendfunction IntentClassifier(; tokenizer::TextEncoders.AbstractTransformerTextEncoder, model::HuggingFace.HGFRobertaForSequenceClassification,) IntentClassifier(tkr, mod)endfunction get_hidden_state(clf::IntentClassifier, query::Union{AbstractString, Vector{<:AbstractString}}) token = encode(clf.tkr, query) hidden_state = clf.mod.model(token).hidden_state return hidden_stateend# This doesn't actually retrain the model, but it retrieves the classifier objectfunction MLJBase.fit(clf::IntentClassifier, verbosity, X, y) cache=nothing report=nothing fitresult = (clf = clf.mod.cls, labels = levels(y)) return fitresult, cache, reportendfunction MLJBase.predict(clf::IntentClassifier, fitresult, Xnew) output = fitresult.clf(get_hidden_state(clf, Xnew)) p̂ = UnivariateFinite(fitresult.labels,softmax(output.logit)',pool=missing) return p̂endMLJBase.target_scitype(clf::IntentClassifier) = AbstractVector{<:Finite}MLJBase.predict_mode(clf::IntentClassifier, fitresult, Xnew) = mode.(MLJBase.predict(clf, fitresult, Xnew))```To test that everything is working as expected, we fit the model and generated predictions for a subset of the test data:```{julia}#| output: trueclf = IntentClassifier(tkr, mod)top_n = 10fitresult, _, _ = MLJBase.fit(clf, 1, nothing, y_test[1:top_n])@time ŷ = MLJBase.predict(clf, fitresult, queries_test[1:top_n]);```## 🤖 Conformal ChatbotTo turn the wrapped, pre-trained model into a conformal intent classifier, we can now rely on standard API calls. We first wrap our atomic model where we also specify the desired coverage rate and method. Since even simple forward passes are computationally expensive for our (small) LLM, we rely on Simple Inductive Conformal Classification.```{.julia}conf_model = conformal_model(clf; coverage=0.99, method=:simple_inductive, train_ratio=train_ratio)mach = machine(conf_model, queries, y)@time fit!(mach)Serialization.serialize("dev/private/simple_inductive.jls", mach)```Finally, we use our conformal LLM to build a simple yet powerful chatbot that runs directly in the Julia REPL. Without dwelling on the details too much, the `conformal_chatbot` works as follows:1. Prompt user to explain their intent.2. Feed user input through conformal LLM and present the output to the user.3. If the conformal prediction set includes more than one label, prompt the user to either refine their input or choose one of the options included in the set.```{julia}mach = Serialization.deserialize("../dev/private/simple_inductive.jls")function prediction_set(mach, query::String) p̂ = MLJBase.predict(mach, query)[1] probs = pdf.(p̂, collect(1:77)) in_set = findall(probs .!= 0) labels_in_set = labels[in_set] probs_in_set = probs[in_set] _order = sortperm(-probs_in_set) plt = UnicodePlots.barplot(labels_in_set[_order], probs_in_set[_order], title="Possible Intents") return labels_in_set, pltendfunction conformal_chatbot() println("👋 Hi, I'm a Julia, your conformal chatbot. I'm here to help you with your banking query. Ask me anything or type 'exit' to exit ...\n") completed = false queries = "" while !completed query = readline() queries = queries * "," * query labels, plt = prediction_set(mach, queries) if length(labels) > 1 println("🤔 Hmmm ... I can think of several options here. If any of these applies, simply type the corresponding number (e.g. '1' for the first option). Otherwise, can you refine your question, please?\n") println(plt) else println("🥳 I think you mean $(labels[1]). Correct?") end # Exit: if query == "exit" println("👋 Bye!") break end if query ∈ string.(collect(1:77)) println("👍 Great! You've chosen '$(labels[parse(Int64, query)])'. I'm glad I could help you. Have a nice day!") completed = true end endend```Below we show the output for two example queries. The first one is very ambiguous. As expected, the size of the prediction set is therefore large. ```{julia}#| output: trueambiguous_query = "transfer mondey?"prediction_set(mach, ambiguous_query)[2]```The more refined version of the prompt yields a smaller prediction set: less ambiguous prompts result in lower predictive uncertainty. ```{julia}#| output: truerefined_query = "I tried to transfer money to my friend, but it failed."prediction_set(mach, refined_query)[2]```Below we include a short demo video that shows the REPL-based chatbot in action.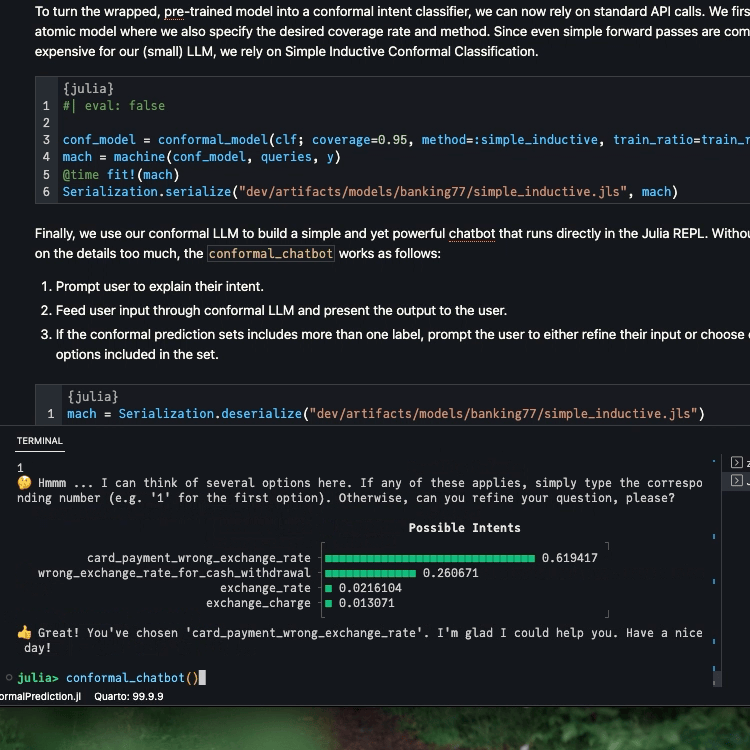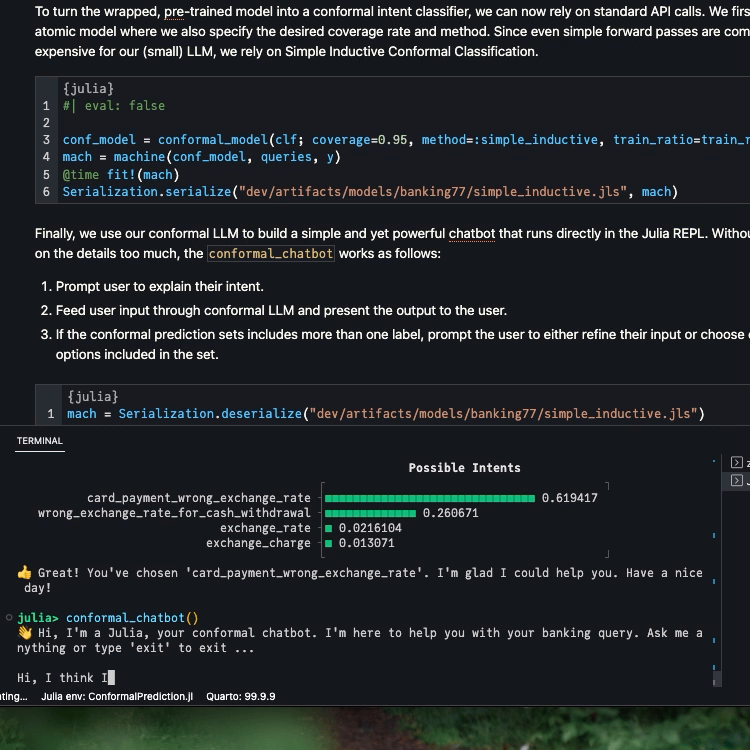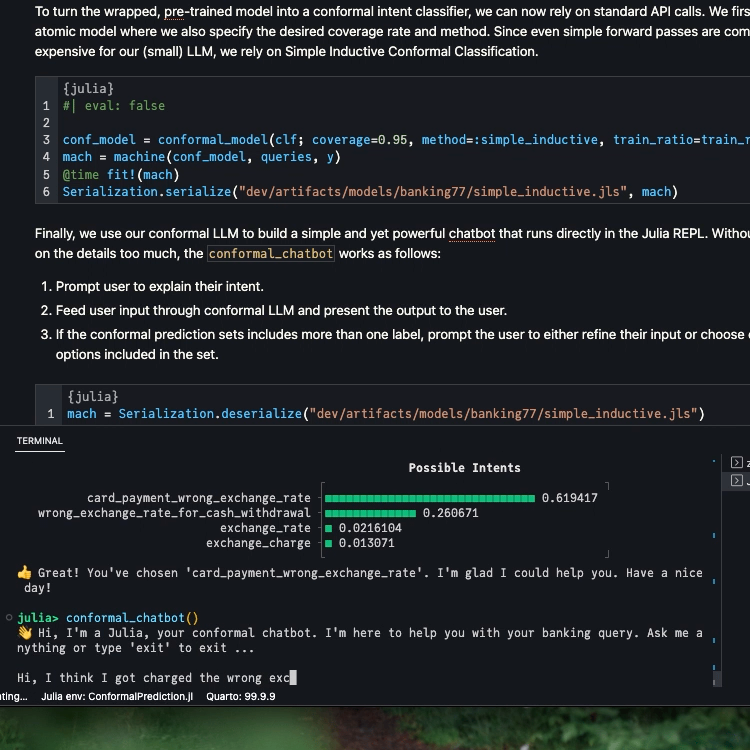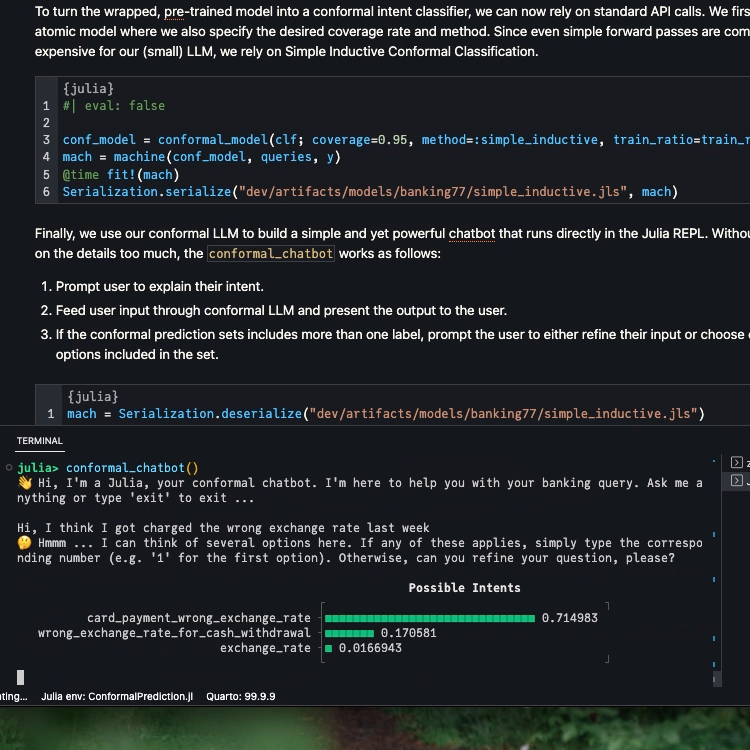## 🌯 Wrapping UpThis work was done in collaboration with colleagues at ING as part of the ING Analytics 2023 Experiment Week. Our team demonstrated that Conformal Prediction provides a powerful and principled alternative to top-*K* intent classification. We won the first prize by popular vote.There are a lot of things that can be improved. As far as LLMs are concerned, we have of course used a fairly small model here. In terms of Conformal Prediction, we have relied on simple inductive conformal classification. This is a good starting point, but there are more advanced methods available (and implemented in the package). Another thing we did not take into consideration here is that we have many outcome classes and may in practice be interested in achieving class-conditional coverage. Stay tuned for more!## 🎓 References